股票市场情感分析项目复盘:从传统机器学习到 DistilBERT、LoRA 与 XGBoost Hybrid
这篇文章整理 DSAI4205 项目中的股票市场情感分析实验。项目目标是对 stock market crash 相关社交媒体文本做三分类情感识别,并比较传统机器学习、轻量 PLM 微调、LoRA 参数高效微调,以及 DistilBERT + XGBoost hybrid 模型的效果。
1. 项目目标
项目任务是对与股票市场、熊市、加密货币和市场崩盘相关的社交媒体文本进行情感分类。标签共有三类:
0:negative1:neutral2:positive
整体目标不是只跑一个模型,而是系统比较多种方案:
- 传统机器学习 baseline:TF-IDF + Logistic Regression、Word2Vec + XGBoost、Word2Vec + Random Forest。
- 串行二阶段分类模型:先粗分类,再细分类。
- DistilBERT + LoRA 参数高效微调。
- DistilBERT-LoRA embedding + XGBoost hybrid 模型。
最终希望得到一个准确率、稳定性、推理速度和可解释性都比较均衡的方案。
2. 数据集与 EDA
数据集共有 1698 条 stock market crash 相关文本,主要来自 Twitter 等社交媒体平台。字段包括:
text:原始文本内容。text_sentiment:情感标签。
原始数据有典型社交媒体特征:hashtag、多语言片段、缩写、口语表达、emoji、编码噪声等。这些特征让任务更接近真实 NLP 分类场景。
标签分布
三类标签分布相对均衡:
| Label | Samples | Percentage |
|---|---|---|
| 1 | 627 | 36.93% |
| 0 | 575 | 33.86% |
| 2 | 496 | 29.21% |
整体没有严重类别不平衡,但 positive 类相对更少,因此后续实验中特别关注 positive recall 和 positive F1。
文本长度
文本长度统计:
| Metric | Value |
|---|---|
| Mean | 150.6 |
| Median | 139.0 |
| Minimum | 11 |
| Maximum | 448 |
不同情感类别的文本长度存在差异:label 0 平均更短,label 1 和 label 2 平均更长。这意味着文本长度本身可能携带一定情感信号。
Hashtag 特征
hashtag 是数据里的重要语义信号。项目中共提取到:
- 总 hashtag 数:5601
- 唯一 hashtag 数:1133
- 平均每条文本 hashtag 数:3.30
高频 hashtag 包括 #stockmarketcrash、#bearmarket、#crypto、#bitcoin 等,说明数据主题集中在市场下跌、熊市、加密货币和投资讨论。
3. 数据清洗
数据清洗目标是减少噪声,同时尽量保留社交媒体文本里的有效语义。主要步骤包括:
- 删除重复样本。
- 修复乱码和编码错误。
- 统一空格、换行和大小写。
- 统一 hashtag 大小写。
- 过滤过短文本。
- 保留英文文本。
- 去除常见 stopwords。
清洗结果:
| Metric | Value |
|---|---|
| Initial rows | 1698 |
| Final rows | 1689 |
| Duplicate rows removed | 9 |
| Garbled rows before | 64 |
| Garbled rows after | 4 |
| Avg length before | 150.55 |
| Avg length after | 151.16 |
| Total hashtags before | 5601 |
| Total hashtags after | 5591 |
可以看到清洗过程只移除了少量重复或异常样本,没有明显改变文本长度和标签分布。
4. Baseline:传统机器学习
第一阶段先建立传统 baseline,用来判断任务难度和后续深度模型是否真的带来提升。
尝试过的方案包括:
- TF-IDF + Logistic Regression
- Word2Vec + XGBoost
- Word2Vec + Random Forest
传统模型的优点是训练快、可解释性相对强、实现成本低;缺点是很难捕捉上下文语义和金融社交媒体里的隐含表达。
最终 baseline 表现大致在 0.55 到 0.58 accuracy 范围,说明仅靠传统特征不足以稳定解决这个三分类任务。
5. 二阶段分类尝试
项目还尝试过 serial model:先做粗粒度二分类,再做细粒度分类。直觉上,这种方式可以把三分类拆成几个更简单的决策。
但实际效果并不稳定,主要问题是 error propagation:
- 第一阶段如果分错,第二阶段无法纠正。
- 三类情感边界并不完全适合硬拆分。
- 社交媒体文本含噪,粗分类阶段容易放大不确定性。
因此二阶段模型没有成为最终方案。
6. DistilBERT + LoRA 微调
第二阶段转向预训练语言模型。考虑到数据规模不大,并且希望控制训练成本,项目选择 DistilBERT 作为 base model,再用 LoRA 做参数高效微调。
LoRA 的核心思想是冻结原模型大部分参数,只在特定线性层中插入低秩矩阵:
其中:
这样可以用更少的可训练参数适配下游任务。
LoRA 迭代过程
项目中 LoRA 不是一次完成的,而是多轮迭代:
- 选择 DistilBERT 作为轻量 base model。
- 先只在部分 attention projection 层插入 LoRA。
- 扩大 LoRA 覆盖到
q_lin、k_lin、v_lin、out_lin。 - 调整 rank 到
r=16,增强表达能力。 - 降低 learning rate,加入 cosine decay、warmup 和 gradient clipping。
- 针对 positive 类识别弱的问题,加入 positive augmentation 和 Focal Loss。

最终 native classifier 使用:
| Component | Setting |
|---|---|
| Base model | distilbert-base-uncased |
| LoRA target modules | q_lin, k_lin, v_lin, out_lin |
| LoRA rank | r=16 |
| LoRA alpha | 64 |
| Dropout | 0.1 |
| Learning rate | 1.5e-4 |
| Epochs | 6 |
| Batch size | 8 |
| Scheduler | warmup + cosine decay |
| Loss | Focal Loss |
7. Focal Loss 与类别平衡
由于 positive 类相对更难识别,项目引入 Focal Loss,让模型更关注难样本:
其中:
- 用于类别权重平衡。
- 用于降低 easy samples 的损失权重。
在本项目中,Focal Loss 的作用不是大幅提高整体 accuracy,而是让三个类别的 F1 更均衡,尤其改善 positive 类。
训练曲线显示,训练 loss 持续下降,评估 macro F1 在前几轮快速上升,并逐渐稳定在 0.75 左右。
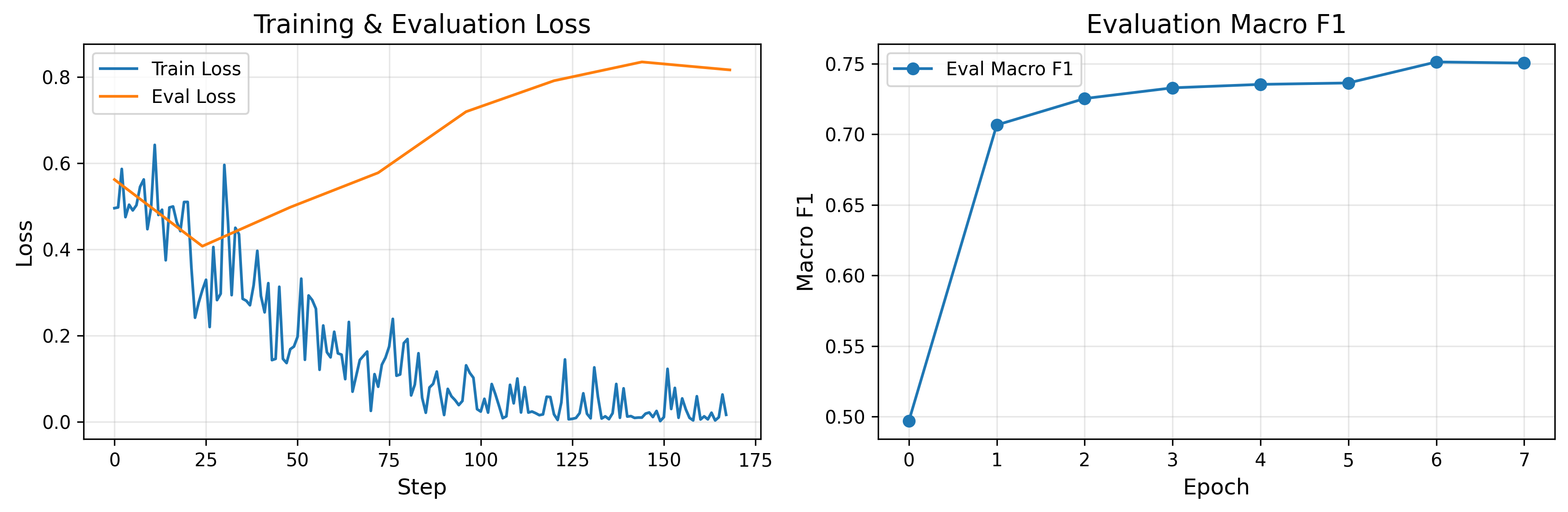
8. DistilBERT + XGBoost Hybrid
除了直接用 DistilBERT 分类头输出结果,项目还尝试了 hybrid model:
- 用 LoRA-tuned DistilBERT 提取句向量。
- 对 token embeddings 做 mean pooling。
- 对 768 维句向量做 L2 normalization。
- 用 XGBoost 做最终三分类。
这样做的动机是结合两类模型的优势:
- DistilBERT 负责语义表征。
- XGBoost 负责稳定、可解释的判别边界。
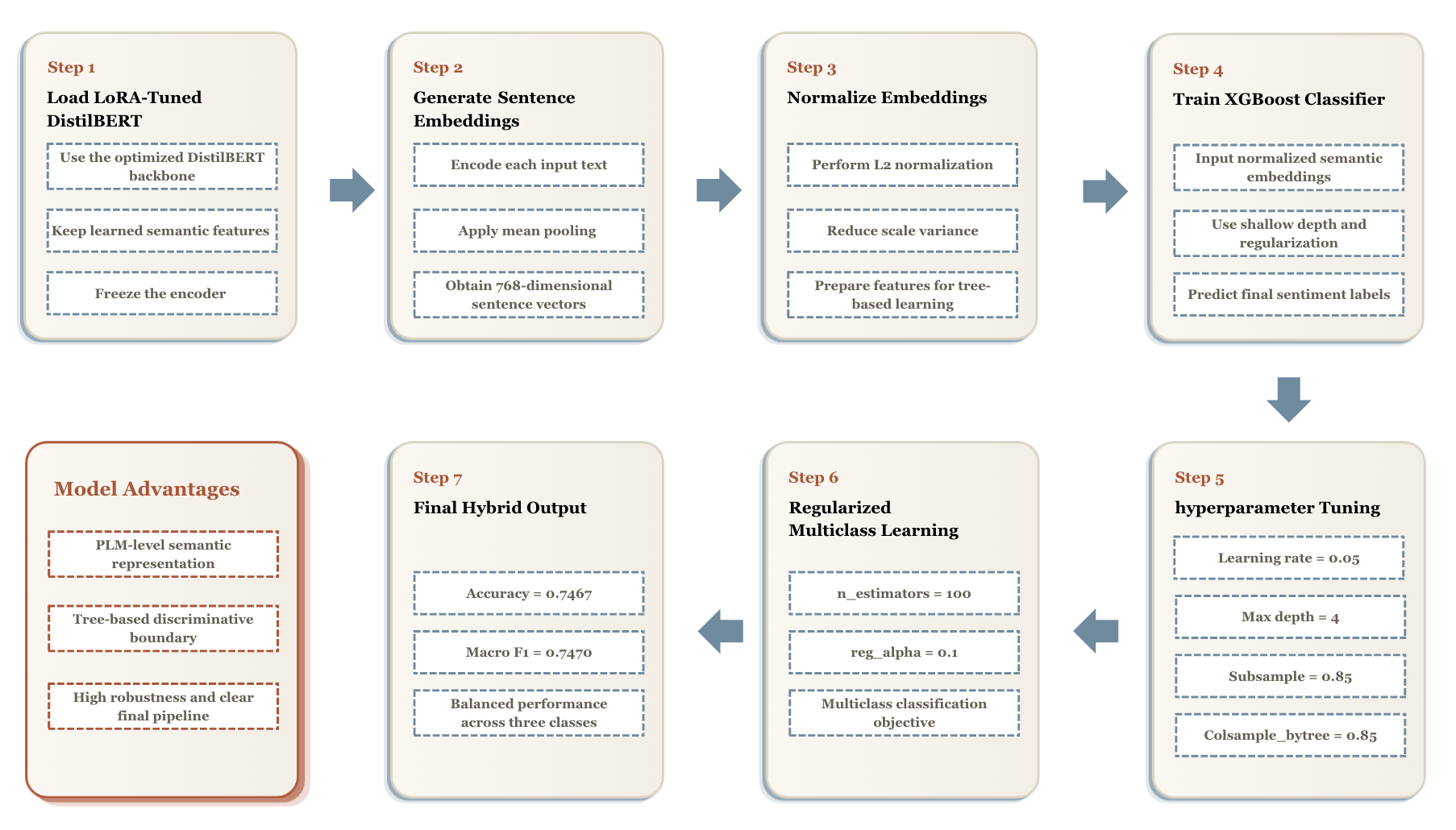
XGBoost 最终配置:
| Hyperparameter | Value |
|---|---|
| learning_rate | 0.05 |
| max_depth | 4 |
| subsample | 0.85 |
| colsample_bytree | 0.85 |
| n_estimators | 100 |
| reg_alpha | 0.1 |
Hybrid 模型最终 accuracy 为 0.7467,macro F1 为 0.7470,和 native classifier 的 0.7500 非常接近。
9. 最终结果
最终比较中,两个最强方案是:
- DistilBERT + LoRA + augmentation + Focal Loss native classifier。
- DistilBERT-LoRA embedding + XGBoost hybrid classifier。
| Model | Accuracy | Negative F1 | Neutral F1 | Positive F1 | Macro F1 |
|---|---|---|---|---|---|
| DistilBERT + LoRA native V2 | 0.7500 | 0.734 | 0.806 | 0.713 | 0.751 |
| BERT-LoRA + XGBoost | 0.7467 | 0.727 | 0.814 | 0.700 | 0.747 |
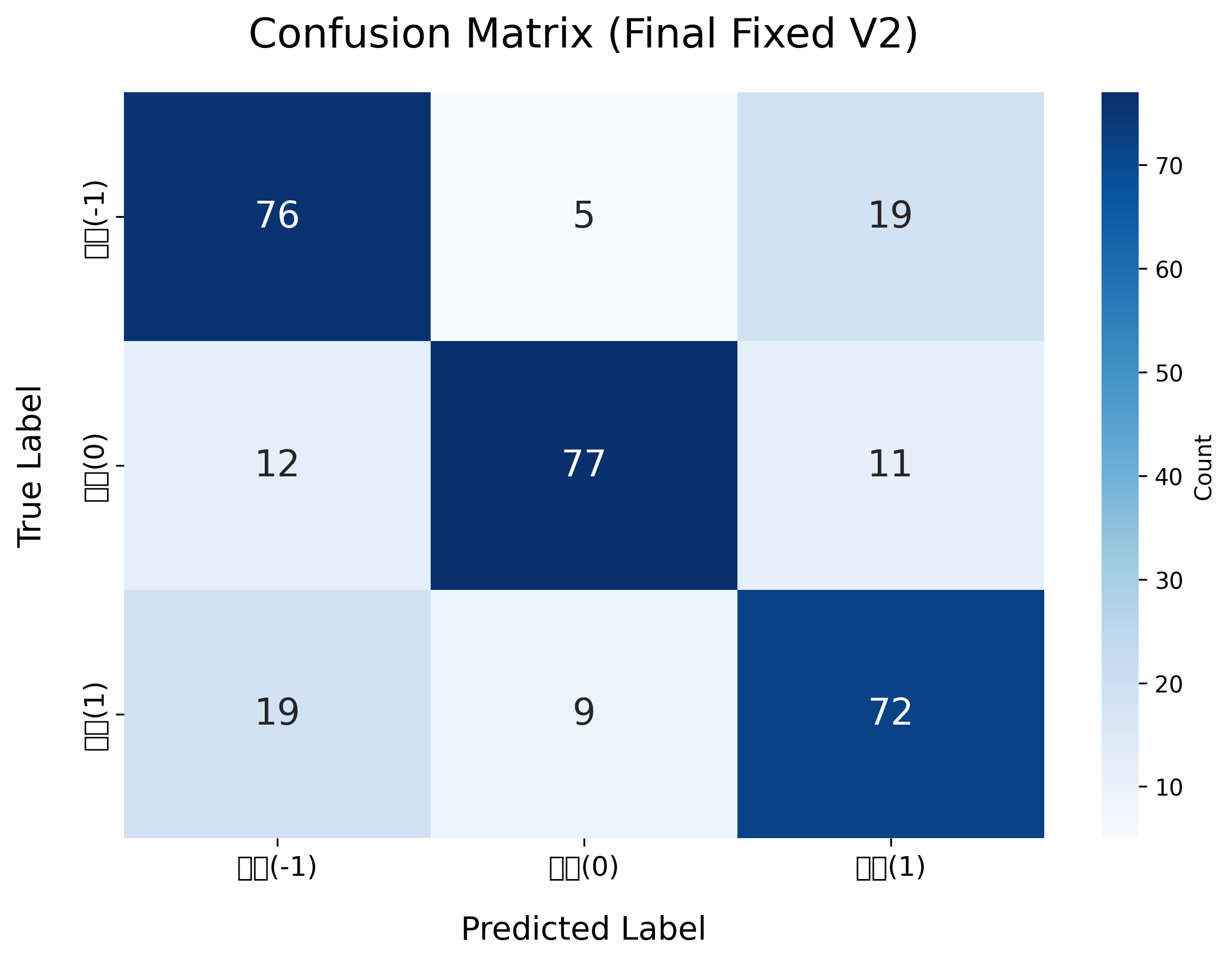
Native classifier confusion matrix
Hybrid model confusion matrix
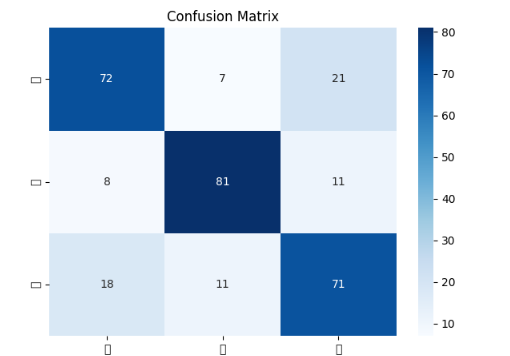
从混淆矩阵可以看到:
- Native classifier 对 negative 和 positive 类略强。
- Hybrid model 对 neutral 类更稳。
- 两个模型整体差距非常小。
10. 实验方案总览
所有主要方案结果如下:
| Scheme | Accuracy | Neg F1 | Neu F1 | Pos F1 |
|---|---|---|---|---|
| Logistic Regression baseline | 0.5767 | 0.650 | 0.560 | 0.520 |
| XGBoost + Word2Vec | 0.5467 | 0.475 | 0.657 | 0.428 |
| Random Forest + Word2Vec | 0.5767 | 0.514 | 0.672 | 0.494 |
| Optimal two-stage model | 0.6433 | 0.692 | 0.686 | 0.536 |
| vinai/bertweet-base | 0.5767 | 0.486 | 0.657 | 0.574 |
| Qwen1.5-0.5B | 0.6667 | 0.670 | 0.671 | 0.660 |
| DistilBERT + LoRA round 4 | 0.6767 | 0.649 | 0.758 | 0.627 |
| DistilBERT + LoRA + Aug + Focal Loss | 0.7500 | 0.734 | 0.806 | 0.713 |
| BERT-LoRA + XGBoost | 0.7467 | 0.727 | 0.814 | 0.700 |
可以看到,性能提升主要来自两个方向:
- 从传统词袋/词向量特征转向预训练语言模型语义表征。
- 针对小样本和类别难点做 LoRA、Focal Loss、augmentation 和训练策略优化。
11. 项目复盘
这个项目最有价值的地方不只是最终 accuracy,而是完整地走了一遍 NLP 小样本分类项目的迭代路径。
一些关键经验:
- baseline 很重要:传统模型提供了任务难度下限,也帮助识别后续提升是否真实。
- 二阶段模型不一定更好:如果第一阶段不稳定,会出现错误传播。
- LoRA 适合小数据集微调:相比全量微调,LoRA 更轻、更容易控制过拟合。
- Focal Loss 能缓解难类问题:尤其适合 positive 类样本不足或识别困难的情况。
- Hybrid model 有部署价值:虽然 accuracy 略低,但推理更快、内存更低、可解释性更强。
12. 后续优化方向
后续可以继续做:
- 模型融合:native classifier 和 hybrid model 做 voting ensemble。
- 更强数据增强:back-translation、EDA、LLM paraphrase。
- 更细粒度 LoRA:不同 attention 层使用不同 rank。
- CoT 数据蒸馏:用更强模型生成可审核的推理标注,再微调小模型。
- 更严格的实验复现:固定 seed、记录数据切分、补充 ablation study。
13. 总结
最终方案 DistilBERT + LoRA + augmentation + Focal Loss 达到 0.7500 accuracy 和 0.751 macro F1;BERT-LoRA + XGBoost 达到 0.7467 accuracy 和 0.747 macro F1。
对作品集来说,这个项目可以展示三件事:
- 能从 EDA 和数据清洗开始做完整 NLP pipeline。
- 能比较传统 ML、PLM fine-tuning、LoRA 和 hybrid model。
- 能用实验结果解释为什么最终选择某个方案,而不是只报一个最高分。
项目代码仓库:
股票市场情感分析项目复盘:从传统机器学习到 DistilBERT、LoRA 与 XGBoost Hybrid
https://richardf123.github.io/2026/06/24/stock-market-sentiment-project/