这篇笔记主要根据 Kolda 与 Bader 的综述论文 Tensor Decompositions and Applications 整理,用来建立张量分解的基础概念。可以把它理解成从矩阵分解继续往高维数组推广:向量是一阶张量,矩阵是二阶张量,三维及以上数组就是高阶张量。
1. 基本记号
张量的 order,也叫 way 或 mode,指的是张量的维度个数。
- 标量是 0 阶张量,通常用小写字母表示,例如 a。
- 向量是 1 阶张量,通常用粗体小写字母表示,例如 a。
- 矩阵是 2 阶张量,通常用粗体大写字母表示,例如 A。
- 三阶及以上的张量通常用花体字母表示,例如 X。
一些常见索引写法:
- 向量 a 的第 i 个元素写作 ai。
- 矩阵 A 的第 (i,j) 个元素写作 aij。
- 三阶张量 X 的第 (i,j,k) 个元素写作 xijk。
- N 阶张量 X 的元素可以写作 xi1i2⋯iN。
如果 X∈RI1×I2×⋯×IN,一般约定第 n 个 mode 的索引范围是 in=1,…,In。
2. Fiber 与 Slice
张量里的子结构很重要,因为很多张量运算其实就是在某个 mode 上对 fiber 或 slice 做矩阵操作。
Fiber 可以理解成“张量中的一根线”。当固定所有索引,只保留一个索引变化时,得到的就是 fiber。
- 对矩阵来说,列向量和行向量就是 mode-1 fiber 和 mode-2 fiber。
- 对三阶张量来说,有三类 fiber:
- mode-1 column fiber:X:jk
- mode-2 row fiber:Xi:k
- mode-3 tube fiber:Xij:

Slice 可以理解成“张量中的一个切片”。当固定除两个索引外的其他索引时,得到的就是 slice。
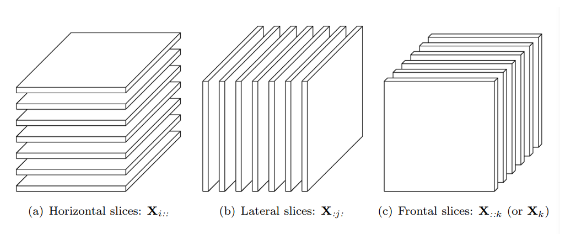
对三阶张量来说,有三类 slice:
- horizontal slice:Xi::
- lateral slice:X:j:
- frontal slice:X::k,也常简写为 Xk
3. 范数与内积
张量的 Frobenius 范数可以看成矩阵 Frobenius 范数的高维推广。对
X∈RI1×I2×⋯×IN
它的范数定义为:
∥X∥=i1=1∑I1i2=1∑I2⋯iN=1∑INxi1i2⋯iN2
两个同尺寸张量 X 与 Y 的内积定义为对应位置元素乘积之和:
⟨X,Y⟩=i1=1∑I1i2=1∑I2⋯iN=1∑INxi1i2⋯iNyi1i2⋯iN
4. Rank-One Tensor
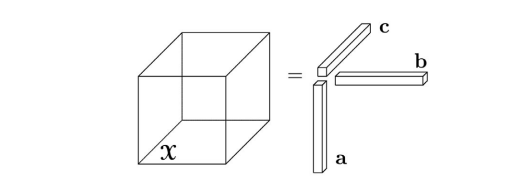
一个 N 阶张量如果可以写成 N 个向量的外积,就称为 rank-one tensor:
X=a(1)∘a(2)∘⋯∘a(N)
其中 ∘ 表示 outer product。元素级别写法是:
xi1i2⋯iN=ai1(1)ai2(2)⋯aiN(N)
三阶 rank-one tensor 可以理解成三个向量 a,b,c 的外积:
X=a∘b∘c
这个概念是 CP 分解的核心,因为 CP 分解就是把一个复杂张量写成多个 rank-one tensor 的和。
5. 对称张量与对角张量
如果一个张量每个 mode 的尺寸都相同,例如
X∈RI×I×⋯×I
它叫 cubical tensor。
如果在任意索引置换下元素值都不变,那么它是 supersymmetric tensor。例如三阶张量满足:
xijk=xikj=xjik=xjki=xkij=xkji
如果只在部分 mode 上对称,就叫 partially symmetric tensor。例如
X∈RI×I×K
如果每个 frontal slice 都是对称矩阵,即
Xk=XkT
那么它就在前两个 mode 上部分对称。
对角张量类似矩阵里的对角矩阵。只有当
i1=i2=⋯=iN
时,元素 xi1i2⋯iN 才可能非零。
6. Vectorization 与 Matricization
Vectorization 是把一个张量按固定顺序重新排列成向量,记作 vec(X)。
如果 A∈Rn1×n2×⋯×nd,一个常用的列优先位置映射是:
col(i,n)=i1+(i2−1)n1+(i3−1)n1n2+⋯+(id−1)n1n2⋯nd−1
这里 i=[i1,…,id] 是元素坐标,n=[n1,…,nd] 是每个 mode 的尺寸。
Matricization 也叫 unfolding 或 flattening,是把张量按某个 mode 展开成矩阵。mode-n matricization 记作 X(n),它会把 mode-n fibers 排成矩阵的列。
对张量分解来说,matricization 很重要,因为许多更新公式都可以转化成矩阵最小二乘问题。
7. n-Mode Product
mode-n product 表示沿着第 n 个 mode 用矩阵或向量去乘张量。
设
X∈RI1×I2×⋯×IN,U∈RJ×In
则 mode-n 矩阵乘法写作:
X×nU
新张量的尺寸为:
I1×⋯×In−1×J×In+1×⋯×IN
元素级别写法是:
(X×nU)i1⋯in−1jin+1⋯iN=in=1∑Inxi1⋯in⋯iNujin
直观理解:矩阵 U 会对 mode-n fibers 做线性变换。
常用性质:
X×mA×nB=X×nB×mA,m=n
X×nA×nB=X×n(BA)
如果乘的是向量 v∈RIn,结果会降低一阶,因为第 n 个 mode 被收缩掉。
8. Kronecker、Khatri-Rao 与 Hadamard 乘积
张量分解公式里经常出现三种矩阵乘积。
Kronecker product:
A⊗B
如果 A∈RI×J,B∈RK×L,则结果尺寸是 (IK)×(JL)。
Khatri-Rao product 是按列做 Kronecker product:
A⊙B=[a1⊗b1,a2⊗b2,…,aR⊗bR]
它在 CP 分解的 matricized 形式中非常常见。
Hadamard product 是对应位置逐元素相乘:
(A∗B)ij=aijbij
几个常用性质:
(A⊗B)T=AT⊗BT
(A⊗C)(B⊗D)=AB⊗CD
(A⊙B)T(A⊙B)=(ATA)∗(BTB)
9. SVD 与 Moore-Penrose 伪逆
不是所有矩阵都能做特征值分解,但任意矩阵都可以做奇异值分解。对
A∈Rm×n
有:
A=UΣVT
其中 U 和 V 是正交矩阵,Σ 是对角矩阵,对角线上的 σ1,σ2,… 是奇异值。
当线性方程
Ax=b
中的 A 不可逆时,可以用 Moore-Penrose 伪逆:
x=A+b
如果 A=UΣVT,则:
A+=VΣ+UT
Σ+ 的做法是把非零奇异值取倒数,零奇异值仍然保持为零。
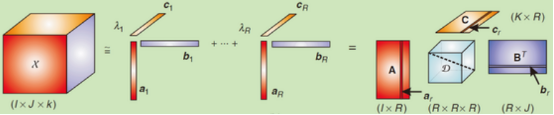
10. CP Decomposition
CP,CANDECOMP/PARAFAC,分解的核心思想是:把一个张量近似表示成若干个 rank-one tensors 的和。
对三阶张量
X∈RI×J×K
CP 分解写作:
X≈r=1∑Rar∘br∘cr
元素形式为:
xijk≈r=1∑Rairbjrckr
如果把所有 ar,br,cr 分别拼成矩阵:
A=[a1,…,aR],B=[b1,…,bR],C=[c1,…,cR]
可以简写为:
X≈[[A,B,C]]
三阶张量的展开形式:
X(1)≈A(C⊙B)T
X(2)≈B(C⊙A)T
X(3)≈C(B⊙A)T
CP-ALS 的常见求解思路是:固定其他因子矩阵,轮流更新某一个因子矩阵,把问题变成最小二乘问题。目标函数可以写成:
A(1),…,A(N)min∥∥∥∥X−[[A(1),A(2),…,A(N)]]∥∥∥∥F2
CP 分解的 rank 是能表示该张量所需的最少 rank-one tensors 数量。
11. CP 分解的唯一性
矩阵的低秩分解通常不唯一。例如:
X=ABT=(AW)(BW−T)T
只要 W 可逆,就能得到不同的因子。
张量 CP 分解在一定条件下反而可能唯一。三阶 CP 分解的一个经典充分条件是 Kruskal 条件:
kA+kB+kC≥2R+2
其中 kA 表示矩阵 A 的 k-rank,也就是任意 k 列都线性无关时最大的 k。
CP 仍然存在两个不可避免的不确定性:
- 列置换不确定性:因子矩阵的第 r 列可以整体换顺序。
- 缩放不确定性:只要 αrβrγr=1,就有
ar∘br∘cr=(αrar)∘(βrbr)∘(γrcr)
12. Tucker Decomposition
Tucker 分解可以看作张量版 PCA。它把原张量分解成一个 core tensor 和每个 mode 上的 factor matrix。
对三阶张量:
X≈G×1A×2B×3C
也可以记作:
X≈[[G;A,B,C]]
其中:
- G 是 core tensor。
- A∈RI×P。
- B∈RJ×Q。
- C∈RK×R。
元素形式为:
xijk≈p=1∑Pq=1∑Qr=1∑Rgpqraipbjqckr
CP 可以看作 Tucker 的特殊情况:core tensor 是超对角张量。
三阶 Tucker 的 matricized 形式:
X(1)≈AG(1)(C⊗B)T
X(2)≈BG(2)(C⊗A)T
X(3)≈CG(3)(B⊗A)T
Tucker 分解通常不唯一,因为可以把一个可逆变换吸收到 core tensor,再用逆变换补偿 factor matrix:
[G;A,B,C]=[G×1U×2V×3W;AU−1,BV−1,CW−1]
常见计算方法:
- HOSVD:对每个 mode 的 unfolding 做 SVD。
- HOOI:在 HOSVD 初始化后,交替优化每个 factor matrix。
13. n-Rank
张量 X 的 n-rank 指 mode-n unfolding 矩阵 X(n) 的列秩:
rankn(X)=rank(X(n))
如果
Rn=rankn(X)
那么 X 可以说是一个 rank-(R1,R2,…,RN) 张量。
这个概念在 Tucker 分解中尤其常用,因为 Tucker rank 本质上就是每个 unfolding 的矩阵秩组合。
14. 其他分解:INDSCAL、CANDELINC、PARAFAC2
INDSCAL 是 CP 的一个特殊情况,适用于在两个 mode 上对称的三阶张量。例如:
X∈RI×I×K
并且 xijk=xjik,则 INDSCAL 模型可写为:
X≈[[A,A,C]]=r=1∑Rar∘ar∘cr
CANDELINC 可以看作带线性约束的 CP 分解。普通 CP 是:
X≈[[A,B,C]]
而 CANDELINC 写作:
X≈[[ΦAA^,ΦBB^,ΦCC^]]
其中 ΦA,ΦB,ΦC 是约束矩阵或变换矩阵。当约束后维度更小,它可以减少计算量。
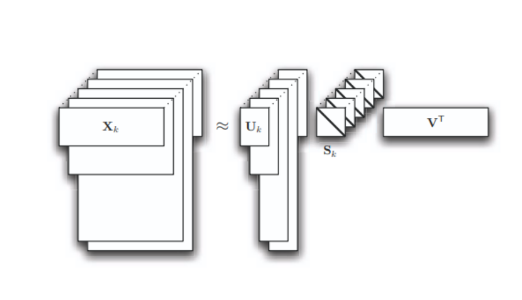
PARAFAC2 严格来说不是对一个固定尺寸三阶张量做分解,而是对一组矩阵做分解:
Xk∈RIk×J,k=1,…,K
这里 Ik 可以随 k 改变。模型形式为:
Xk≈UkSkVT,k=1,…,K
其中:
- Uk∈RIk×R
- Sk∈RR×R,通常是对角矩阵
- V∈RJ×R,在所有 k 上共享
为了增强唯一性,PARAFAC2 通常会加入约束:
UkTUk
在不同 k 上保持不变。
15. 总结
这篇笔记可以按下面这条线理解:
- 先掌握 tensor 的基本索引、fiber、slice、norm、inner product。
- 再理解 rank-one tensor,因为 CP 分解就是 rank-one tensor 的求和。
- Matricization 和 Khatri-Rao product 是 CP/ALS 公式的关键。
- Tucker 分解更像高阶 PCA:用 core tensor 表示不同 components 之间的交互。
- PARAFAC2 适合一组矩阵尺寸不完全一致,但仍希望共享某些潜在结构的场景。
从机器学习角度看,张量分解可以用于降维、缺失值补全、多视角数据建模、推荐系统、时序数据分析和多模态数据建模。后续如果要真正做实验,可以从 Python 的 tensorly 库开始,把 CP、Tucker、PARAFAC2 都跑一遍。